
Building an AI Data Analyst with LLMs - Part 3
Designing the system and its components

This post is the third in a series where I talk about building an Open Source AI Data Analyst using LLMs.
In Part 1, we speak about the motivation behind building such an agent.
In Part 2, we list some of the challenges that stand in our way and start thinking of a solution.
In this article, we’ll dive deeper into the design of a solution and start writing down our requirements for all the different components.
I’m sharing the source code for all I build on this Github repo.
Welcome back to the series folks. If you’re joining in at this point, we’re trying to build an AI Data Analyst using LLMs.
System Specification
Requirements
When I say “AI Data Analyst”, we mean a machine based agent or system such that:
It is capable of understanding the data that lies inside your data warehouse.
You should be able to ask it business or data questions using natural language.
It should look for data models in your warehouse that contain the answers to your question and respond with the queries, charts or dashboards that give you the insights you need to make decisions.
You should be able to let it know if the answer so provided was correct and if not, you should be able to provide a correction that the system learns from, and uses to improve future responses.
Constraints
Here are some technical constraints that I’m working with while trying to build this system:
I would like the entire system to be built in a way that I can offer the source code and users can self-host. At the same time, I would also like to offer a managed service where users can pay me to host the system for them and use it like a SaaS product.
I would like the users to be able to interact with this system using tools that they already use. At the time of writing this article, I think that interface should be Slack - so for the moment we’re going to try and build this as a Slack bot. This may change in future.
Birds Eye View
Let’s start by taking a birds-eye view of the entire system and later we can zoom into the individual components to see how they should be built.
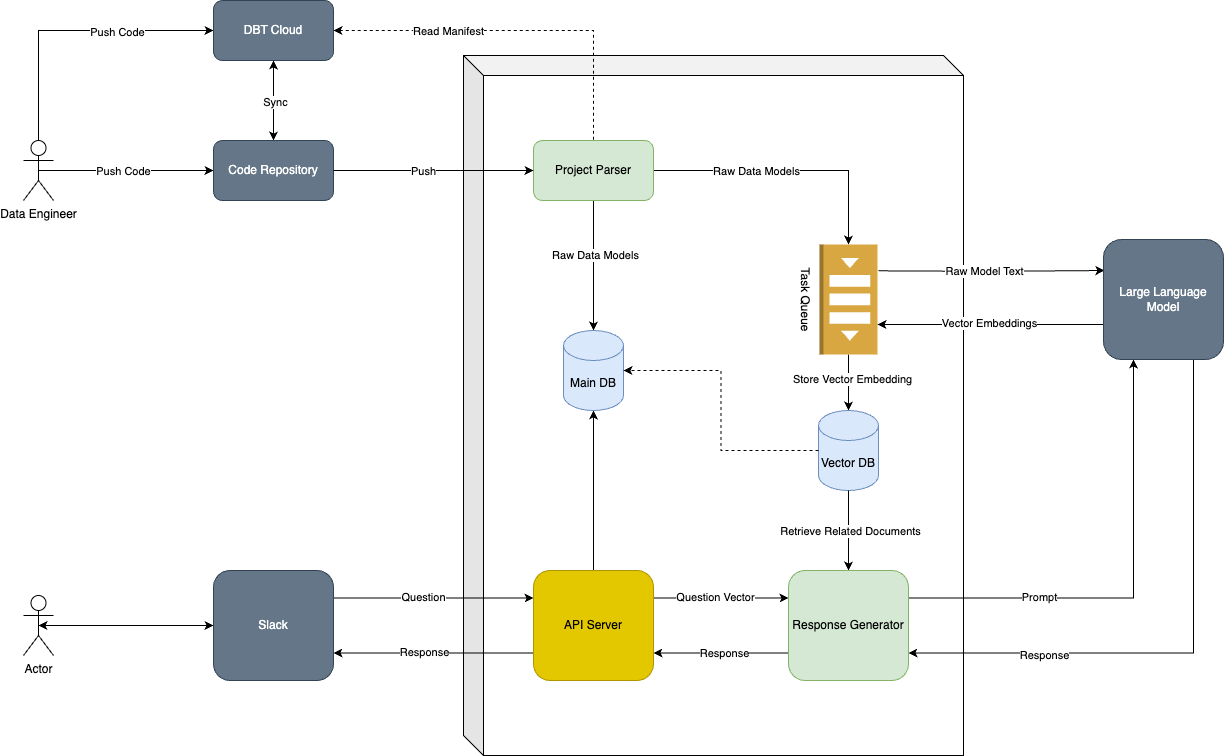
Model Indexer
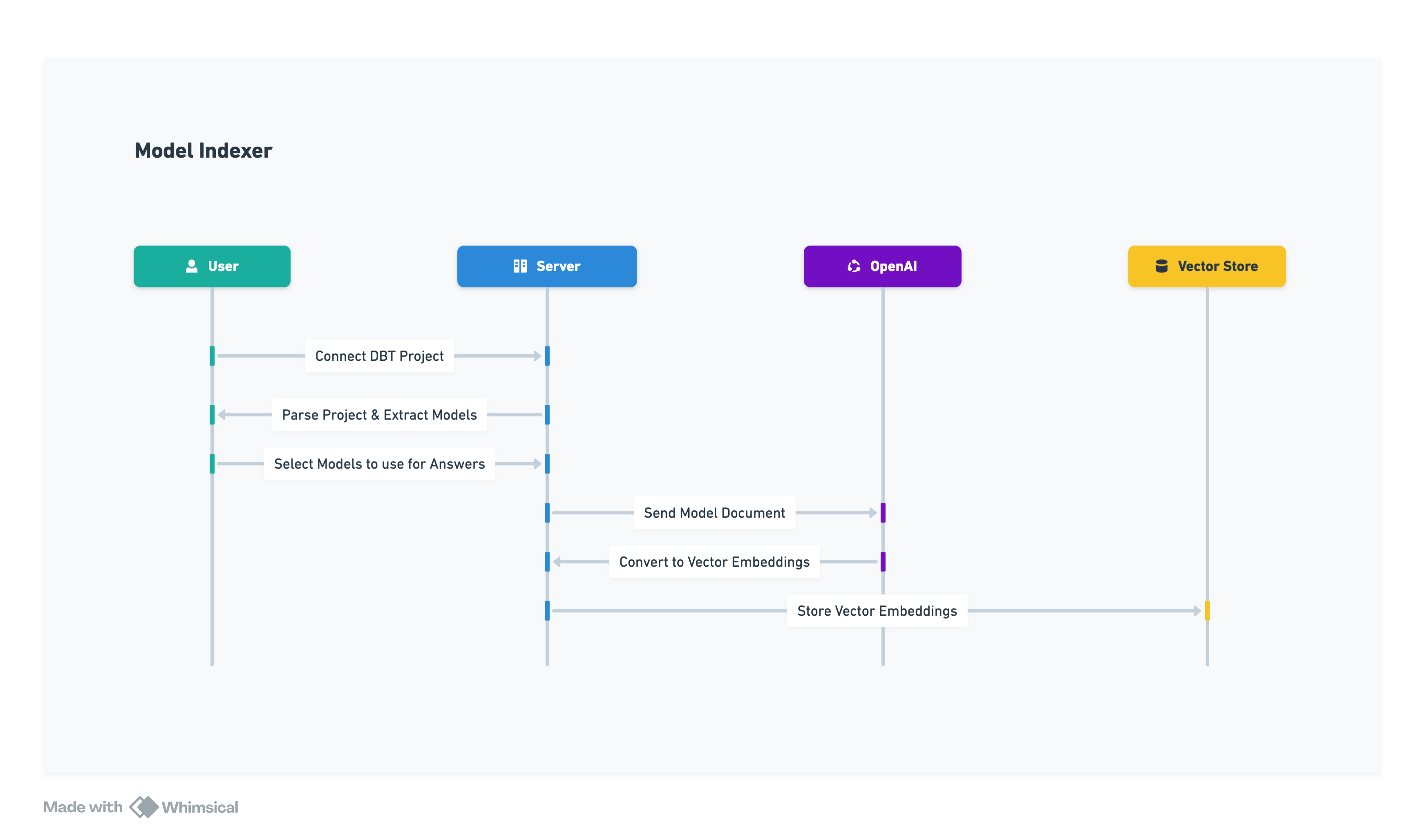
The first major component of our system is the model indexer. The model indexer is responsible for creating a “knowledge base” that our agent will use to respond to data related questions.
In dbt, all models are stored as individual SQL files. dbt also allows you to write documentation for your models and columns contained within them in the form of YML files. You can split your documentation into as many or as few YML files as you like and they can be located anywhere within your project.
Ideally, our system should use model documentation to answer questions. In case this documentation is not available, we should be able to use LLMs to deduce the meaning of those models using the raw SQL used to create the model and its upstream dependencies.
Requirements
We need our model indexer to be able to parse our DBT project to extract information about our data models and the relationships between them. This includes:
Reading all SQL files to create a list of models as well as extract the raw SQL used to create these models.
We also walk through all the cross model references to create a lineage graph for all our models.
Reading all YML files to extract all the user defined documentation for these models.
Writing documentation for models is not compulsory. When written, the documentation can be spread arbitrarily throughout the project so we’ll need to match any documentation we find to the definition of the model we found above.
In case documentation is not available, we should be able to interpret the output of a model by reading the raw SQL used to create the model and its upstream dependencies.
Question Answerer
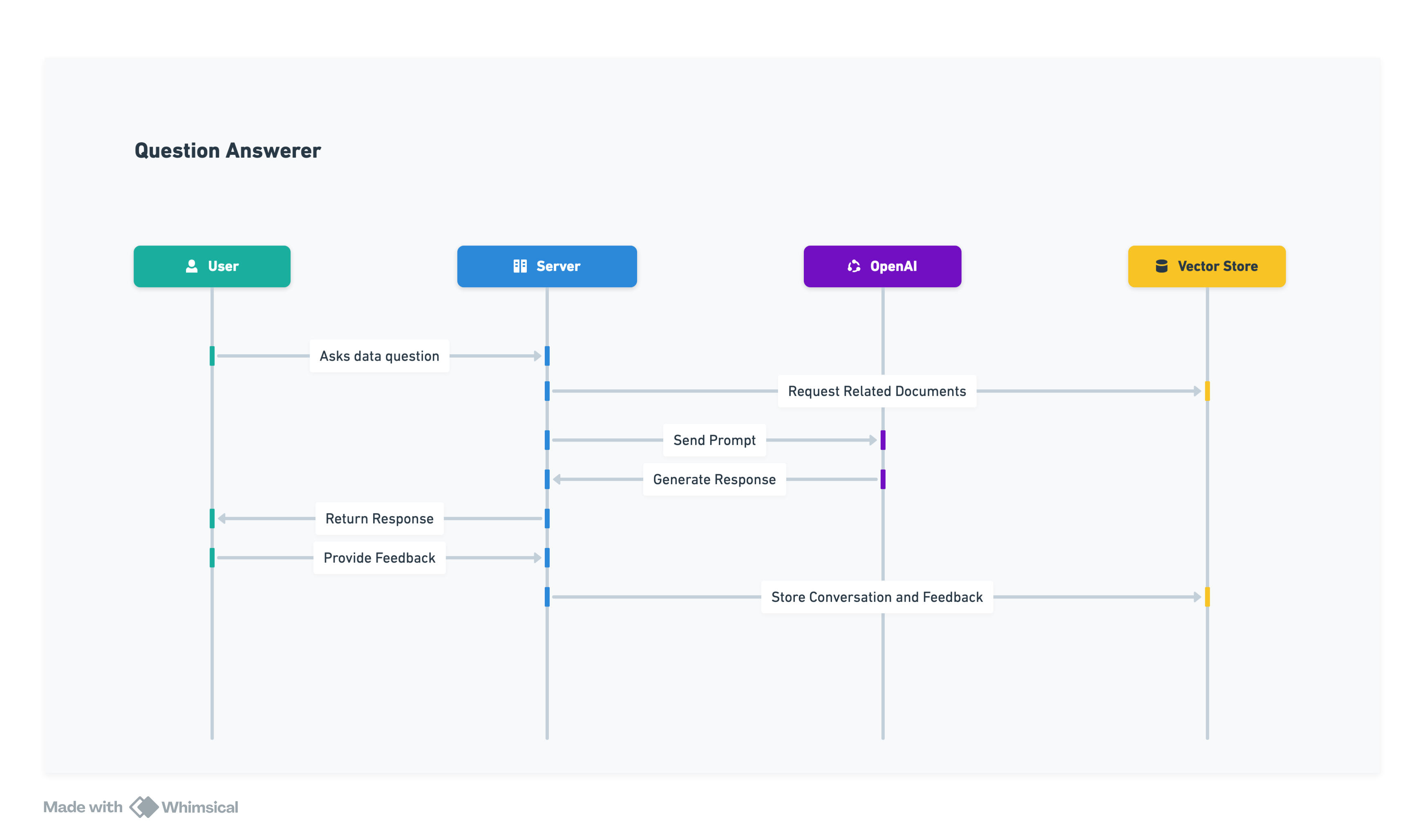
The second major component of our system is responsible for using our knowledge base to respond to questions about data.
Requirements
Our question answered should:
Be able to receive questions in natural language.
Find the models that should be used to answer this question based on their documentation.
In addition to the user defined documentation, the system should also look at LLM generated interpretation to search for additional models.
Look through conversation history to check if this question was answered before and if the answer was satisfactory, or if there was a correction provided.
Use this information so obtained to create a prompt that is sent to a language model to generate an answer.
Be able to accept feedback on the answer provided and store this for future reference.
Conclusion
That concludes the design process for our AI Data Analyst. In the next article, we’ll start building our first system - the model indexer.
Can there be enhancement to have a locally trained LLM within an enterprise boundaries instead of Open AI ... specific to enhance security / "data security" aspects of data schemas...